
雖然還不完整,不過 Heresy 之前已經整理了好一些 Kinect for Windows SDK v2 的各項功能的程式寫法了;沒意外的話,之後應該還是會慢慢加的。
而這一篇,則是先跳離 Kinect for Windows SDK 其他核心功能的部分,來研究一下 Kinect Fusion 這個 3D 模型重建的功能(很久之前的介紹)該怎麼使用吧~
實際上,Kinect Fusion 的功能在 Kinect for Windows SDK 1.7 的時候,就已經被加入當時第一版 Kinect for Windows SDK 的 Toolkit 裡了;不過由於當時 Heresy 並沒有在使用 Kinect for Windows SDK,所以也沒有研究。
而現在新的 Kinect for Windows SDK v2 還是有提供 Kinect Fusion 的功能,而 Heresy 又有相關的需求了,所以就來看看怎麼玩吧~不過,這篇還不會進入程式的部分,而是先透過官方提供的範例程式,來講一下 Kinect Fusion 的概念。
基本概念
首先,使用 Kinect Fusion 來建立 3D 模型基本的方法,大致上就是:
對空間中的一個區域,拿著 Kinect 感應器平穩、緩慢地移動,讓感應器可以拍攝到這個區域不同的角度,藉此來完成整個區域內物體的 3D 重建。
而它的原理可以參考下面的示意圖(MSDN):
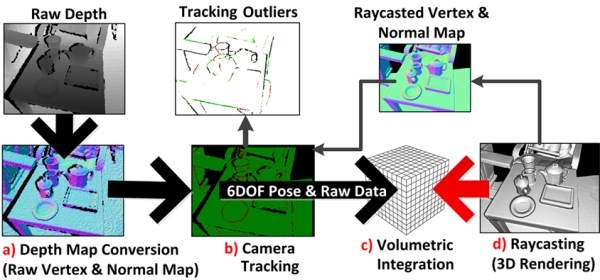
基本上他會在空間中建立一個虛擬的方塊、對應到要進行 3D 重建的範圍;而這個方塊的空間裡面則會再根據設定、細切為一小顆一小顆的點(Voxel),用來做資料的儲存、代表空間中的一點是否有東西。而這樣類型的資料,一般是會被稱為「Volume」,看起來會像上圖中的「c」的那個立體方格。
這個 Volume 的大小,就決定了可以進行 3D 重建的範圍大小,它裡面的 Voxel 的數量,則決定了重建出來的模型的精細度。所以,理論上,Voxel 的數量是越多越好的!但是,由於 Volume 類型的資料需要使用相當大的記憶體,所以其實是不能無限制地加大的;再加上 Kinect Fusion 實際上是在顯示卡上做處理的,所以能使用的量一般又比系統記憶體來的少,所以它的大小會是有限的。
而在建立出這個 Volume 之後,Kinect Fusion 則會在捕捉到新的深度影像時,將資料做一些轉換(上方示意圖的 a)、然後和現有的資料進行比較、計算出攝影機的位置角度資訊(上方示意圖的 b)。在計算出相對的位置之後,就可以計算出深度感應器取得的三度空間點位資料在 Volume 裡面的對應位置,然後再整合進前面建立出的 Volume 內,計算 Volume 裡面的各個 voxel 的值。
最後,當拍攝結束後,就可以根據這個 Volume 的資料,來重新建立出多邊形的 3D 模型了。
官方範例程式
而如果只是想要使用 Kinect Fusion 來掃描、重建 3D 模型的話,其實不需要寫程式、只要使用微軟 Kinect for Windows SDK v2 提供的範例就可以了~
打開 Kinect for Windows SDK v2 的 SDK Browser,裡面會看到三個和 Kinect Fusion 相關的範例,分別是「Kinect Fusion Basics-D2D」 、「Kinect Fusion Explorer-D2D」和「Kinect Fusion Explorer-WPF」;這三個範例都可以直接點選右下方的「Run」、直接執行。

其中,「D2D」和「WPF」是代表是用不同的圖形介面來做顯示的,而「Basic」是只有最基本功能的精簡版、「Explorer」則是設定較為完整的版本。
下圖就是「Kinect Fusion Explorer-WPF」的介面。

其中,程式上半部就是顯示的畫面,下半部紫色框的區域則是控制參數。
在顯示區域右上方的灰階影像,是目前的 Kinect 捕捉到的深度影像;而左側較大的區域,則是目前 3D 模型重建完成的結果。至於右下方的畫面,則是目前深度影像在進行追蹤、位置計算後的狀況,有顏色的部分是代表沒辦法正確對上的區域(上方示意圖中的「Tracking outliers」)。
在使用上,基本上程式一執行起來後,就已經開始進行掃描了;此時他會以預設的設定、以及目前感應器看到的範圍來做為初始條件,進行掃描。而如果要修開參數、或重新開始的話,就是要先把參數調好、並把感應器對準要掃的範圍,按下左側的「Reset Reconstrucion」、讓程式重新開始。
而當掃描完成後,則可以直接按「Create Mesh」,把結果儲存下來。
參數說明
Kinect Fusion Explorer-WPF 這個範例程式的控制功能,主要就是下方紫色的控制/參數區;個人覺得他的分類滿凌亂的,感覺沒有分得很好就是了…
首先,在這區的最左側,是「Action」的部分,其功能由上而下依序是:
-
「Create Mesh」是在掃描完後、用來輸出 3D 模型檔用的,可以選擇 STL、OBJ、PLY 三種格式。
-
「Reset Reconstrucion」則是用來重設狀態用的。如果是在結束後、或是掃壞了,想要重新開始掃描的話,就需要使用這個功能。
-
「Use Camera Pose Finder」…這個選項是去調整內部用來做感應器位置判斷(Camera Tracking)的方法。至於他和預設方法的差異,Heresy 也還不確定。
-
「Reset Virtual Camera」是用來重新設定檢視的視角用的。基本上只有在沒有勾選右側的「Kinect View」時才有用。
在中間上方的「Image Options」則是用來控制顯示的畫面,以及捕捉時的影像性質用的。
-
「Capture Color」如果有被勾選的話,那在結果畫面那邊,就可以看到彩色的模型;而如果最後輸出成 PLY 檔的話,3D 模型也會有色彩的資訊。
-
「Mirror Depth」則是在處理深度影像前會先把畫面做鏡像,所以最後的模型也會左右相反。
-
「Pause Integration」是暫停處理,按下去之後,程式就不會把新的畫面整合到結果裡。
-
「Volume Graphics」則是在結果畫面把整個 colume 的範圍、以及現在的 Kinect 視角畫出來;也就是在上面的截圖中的大綠色框框、以及裡面的黃色錐形。
-
「Kinect View」如果有勾選的話,那結果畫面會隨著感應器目前的角度而變化,不能自己調整;取消勾選後,則可以透過滑鼠來控制要看的角度。如果調到不知道東西到哪去了,則可以點選左下方的「Reset Virtual Camera」來恢復到原始的位置。
在中間下方的「Depth Threshold」是用來控制要使用的深度範圍的,這樣可以避免感應器拍到太近或太遠的東西;調整的結果會即時反映在右上方的深度畫面上。
而紫色框的右側,則有「Volume Max Integration Weight」、「Volume Voxels Per Meter」、「Volume Voxels Resolution」三區。
其中最上方的「Volume Max Integration Weight」是用來控制在整合深度影像時、時間軸上的平滑化參數。值越小深度的雜訊越明顯,但是相對地它比較適合動態的環境,可以較快地把物體掃描好;調高的話,場井裡面如果有忽然冒出一個東西的話,他會需要比較久的時間才會把新的物體整合進去,不過相對地整體雜訊會比較少。
而「Volume Voxels Per Meter」和「Volume Voxels Resolution」這兩組參數,則決定掃描的範圍、以及精細度。
在前面一開始已經有提過,Kinect Fusion 的概念是先去建立一個 Volume 出來,透過裡面的 voxel 來記錄空間中的狀況。而這邊的「Volume Voxels Resolution」這組參數,就代表這個 Voulme 裡面到底有多少個 voxel;他的設定在三個軸向可以不一樣,讓使用者可以根據要掃描的範圍作調整。
「Volume Voxels Per Meter」則是設定「一公尺裡面有多少個 voxel」,所以它和「Volume Voxels Resolution」組合起來,就是可以掃描的範圍。
比如說假設「Volume Voxels Resolution」設定為 512 x 512 x 256、「Volume Voxels Per Meter」設定成 256 的話,就代表可以掃描的區域大小會是 2 x 2 x 1 m3 這樣的範圍。而如果把、「Volume Voxels Per Meter」降低到 128 的話,那可以掃描的區域大小則會變成 4 x 4 x 2 m3。
「Volume Voxels Resolution」的值越大,精細度會越高,但是使用的記憶體量會越大、計算也會越慢。在「Kinect Fusion Explorer-WPF」這個範例裡面、最高值只可以拉到 512,但是如果改成 D2D 的範例,值的上限則會是 640;而如果是自己使用 SDK 來開發的話,值甚至可以更高,但是最終還是取決於使用的顯示卡到底有多好、記憶體多大了。
以 Heresy 這邊自己的測試,要用 512 x 512 x 512 的解析度來執行的話,顯示卡的記憶體會被用超過 1GB,加上本來被系統、其他程式用的,顯示卡應該會需要至少 2GB 的記憶體才夠;而以現在主流的顯示卡配置來說,這應該不算太大的需求。
而「Volume Voxels Per Meter」的值越大的話,細緻度會越高,但是可以掃描的範圍就會越小,所以要設定成多少,應該是要根據要掃描的範圍大小來考慮的。
Kinect Fusion 的基本原理、還有範例的使用大概就這樣了。之後再來整理要怎麼用他提供的 API 來開發程式吧~