
最近在弄新的系統的時候,同事在 Windows 上寫的 PHP 程式在要搬到 PHP Apache Docker 的時候,出現了一個奇怪的問題;那就是它會出現下面的錯誤:
Warning: session_start(): Cannot start session when headers already sent in XXX.php on line X
這個錯誤還算滿明確的,基本上就是在呼叫 session_start() 這個 PHP 的函式之前,就先粗出了其他的內容所造成的。
但是仔細檢查過檔案後,卻發現其實根本沒有輸出任何東西啊?
就算整個檔案改成最簡單的
<?php session_start() ?>
都還是會有同樣的問題。
原因
經過了好一段時間的測試和研究,才發現,原來如果用 Visual Studio 儲存成 UTF-8 的檔案,都會有這樣的問題。
後來找了一下,才在《php session_start header already sent encoding utf-8 issue》這篇文章發現、可能 BOM 的問題。
所謂的 BOM 全名是「Byte Order Mark」,中文似乎是叫做「位元組順序記號」(維基百科)。
它基本上是一個特殊的 Unicode 字元,在 UTF-8 會是「0xEF,0xBB,0xBF」、在 UTF-16 則是「U+FEFF」,如果要找的話,也可以搜尋「」。
如果把一個檔案儲存成 UTF-8 + BOM 的話,那這個字元就會被加在文件的一開始、告訴要讀取他的人,接下來資料的「endian」;也就是 big-endian 或是 little-endian(維基百科)。
而也由於他會在檔案一開始加入這個看不到的特殊字元,所以如果網頁伺服器不認識這個特殊字元的話,就會把它當作要顯示的資訊送出去,所以才會導致 PHP 在執行 session_start() 的時候出現錯誤。
解決方法
至於解決方法呢?就是把檔案重新儲存成不包含 BOM 的版本就可以了。
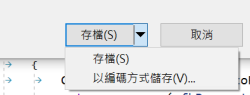 在 NotePad++(官網)存檔的時候,應該是可以直接選擇編碼;而在 Visual Studio 的話,實際上也可以透過「檔案」、「另存 xxx」,然後點選「存檔」旁邊的向下三角形、選「以編碼方式儲存」。
在 NotePad++(官網)存檔的時候,應該是可以直接選擇編碼;而在 Visual Studio 的話,實際上也可以透過「檔案」、「另存 xxx」,然後點選「存檔」旁邊的向下三角形、選「以編碼方式儲存」。
之後,裡面就可以在接近最末端的地方,找到一個「Unicode (UTF-8 無簽章) – 字碼頁 65001」的選項了。

而如果檔案很多的話,該怎麼辦呢?
在《How can I remove the BOM from a UTF-8 file?》這邊有提到,如果是在 Linux 平台的話,其實可以透過「sed」這個指令來處理:
sed -i '1s/^xEFxBBxBF//' orig.txt再透過 bash script 的話,則可以寫成:
#!/bin/bash for f in *.php; do sed -i '1s/^xEFxBBxBF//' $f done
這樣只要執行這個 script,就可以將資料夾下的所有 PHP 檔、都把 BOM 拿掉了~