
 話說,NVIDIA CUDA 這個 GPGPU 的程式開發架構從 2007 年推出 1.0 版發展至今,也已經好一段時間了;這段期間,NVIDIA 也不斷地推出新的 GPU 架構、以及對應的新版 CUDA SDK,在效能和功能上做強化,基本上應該也算是目前最成熟的 GPGPU 開發環境之一。
話說,NVIDIA CUDA 這個 GPGPU 的程式開發架構從 2007 年推出 1.0 版發展至今,也已經好一段時間了;這段期間,NVIDIA 也不斷地推出新的 GPU 架構、以及對應的新版 CUDA SDK,在效能和功能上做強化,基本上應該也算是目前最成熟的 GPGPU 開發環境之一。
而日前,NVIDIA 也發表了還沒正式發布的最新版的 CUDA 6.0(現在還沒有可以下載的 SDK)的一個主要的功能,那就是「統一記憶體」(Unified Memory);原文可以參考官方的《Unified Memory in CUDA 6》一文。
在以往的 GPGPU 程式開發,不管怎樣,基本上都還是需要先把資料從 CPU 管理的系統記憶體(host、下圖左邊的 System Memory)、複製到顯示卡管理的記憶體(device、下圖右邊的 GPU Memory)上,然後才能開始使用 GPU 做計算;而計算完成之後,也需要手動把資料複製回 CPU、才能進一步處理這筆計算好的結果。
這個流程在硬體的架構上,基本上暫時應該還是無法避免的(AMD APU 的 HSA 應該算是特例);而 CUDA 6 的 Unified Memory,就是希望可以在程式開發上,可以針對這點做簡化、降低開發程式的門檻。
下圖就是 NVIDIA 提供的示意圖,左邊就是目前的狀況,而右邊則是引入 Unified Memory 的技術後的情況。
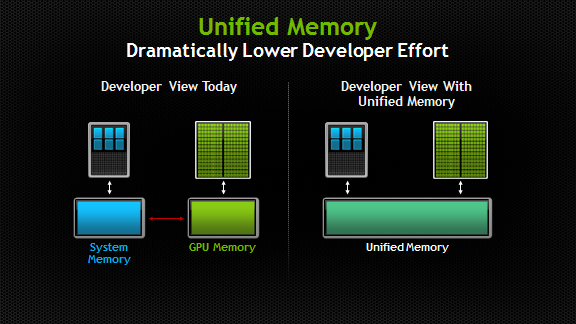
Unified Memory  基本上就是提供一個整合了 CPU 和 GPU 的記憶體管理區域,這裡面的記憶體可以以指標的形式、被 CPU 或 GPU 來做存取;系統會自動地在 host 與 device 之間,做記憶體搬移的動作,開發者不用再去自行做記憶體的複製動作。
這樣的好處,就是大幅地減低了記憶體管理上的複雜度,因為只要把這部分的工作都丟給系統去做就好了!開發者要做的,只是把配置記憶體的方法,從本來的 malloc() 換成 cudaMallocManaged(),釋放記憶體從 free() 變成 cudaFree() 就可以了。
下面就是官方提供的一個簡單的例子:
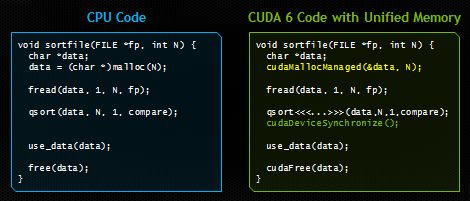
可以看到,在右方使用 CUDA 6 Unified Memory 的情況下,使用 cudaMallocManaged() 配置出來的記憶體,不但可以被 CUDA 的 kernel 執行,也可以被 CPU 上的 fread() 寫入資料。
而如果是要在 C 的環境下使用的話,基本上也可以透過自定義一個類別的建構子和解構子來做到更方便的管理;這部分可以參考《Unified Memory in CUDA 6》內的「Unified Memory with C 」一節,在這邊就不贅述了。
不過,這樣的自動記憶體管理,理論上應該還是會帶來一定程度的效能損失的。NVIDIA 到目前為止,都還沒有提及到這部分,所以使用這個技術到底對效能會有多大的影響,應該就要等 SDK 正式發布後、有人去試過才知道了;而到時候,是否要接受這樣的便利性/效能損失,就要看開發者的取捨了。
最後附帶一提,Unified Memory 只能用在 Kepler 架構的 GPU 上(Compute Capability 3.0 ),使用的作業系統也有一些限制(64bit Windows 7 、Linux Kernel 2.6.18 ),所以還在舊的開發環境的話…要用這項新功能的話,除了要等新的 SDK 發布、應該也等更新開發環境了~
除了 Unified Memory 外,CUDA 6 另外兩個被 highlight 出來的功能,還有:
-
Drop-in Libraries
Automatically accelerate applications’ BLAS and FFTW calculations by up to 8X by simply replacing the existing CPU libraries with the GPU-accelerated equivalents.
-
Multi-GPU scaling
The re-designed BLAS GPU library automatically scales performance across up to eight GPUs in a single node, delivering over nine teraflops of double precision performance per node, and supporting larger workloads than ever before (up to 512GB). The re-designed FFT GPU library scales up to 2 GPUs in a single node, allowing larger transform sizes and higher throughput.
這感覺上有點像是將之前的zero copy做一個改善。