
在前一篇《Kinect Fusion Part 1:C API 基本使用》,基本上已經把不包含顏色資訊的 Kinect Fusion 的程式寫過一遍了。而這一篇,則是來整理一下,怎麼把顏色資訊也加到掃描結果上吧~
首先,之前不包含色彩的版本,是使用「INuiFusionReconstruction」這個介面來做操作的,而當時也有提過,如果要有色彩的資訊,要改用「INuiFusionColorReconstruction」這個介面;他和 INuiFusionReconstruction 的操作方法基本上都一樣,不同的地方最主要只在於在呼叫 ProcessFrame() 的時候,需要多給他一張對應深度資訊的彩色影像了~
當然,由於在重建模型時也需要包含色彩資訊(這邊是 per-vertex color 的形式),所以在呼叫 CalculateMesh() 時產生的結果,資料型別也會從「INuiFusionMesh」變成「INuiFusionColorMesh」。
初始化
INuiFusionColorReconstruction 在初始化的時候,是要透過 NuiFusionCreateColorReconstruction() 這個函式來完成物件的建立;而其所需要的參數和 NuiFusionCreateReconstruction() 完全相同,所以在這邊就不重複描述了,有需要請直接參考《Kinect Fusion Part 1:C API 基本使用》。
另外,由於這部分的內容很多都是基於沒有色彩的版本做延伸的,所以建議要看這篇的話,還是先把《Kinect Fusion Part 1:C API 基本使用》看過一遍、會比較合適。
資料轉換
在之前也有提到,Kinect Funsion 的 API 所接受的影像格式,都是 NUI_FUSION_IMAGE_FRAME 這個自定義的格式,像是深度影像在使用時,也需要把它先轉換成符合需求的格式。而彩色影像在使用時,也是需要轉換成 NUI_FUSION_IMAGE_FRAME 的~而且,和深度影像比起來,轉換的過程會更為麻煩一點。
首先,Kinect Fusion 所需要使用的彩色影像,其內容必須對應深度影像;這包含了解析度、以及每個像素的對應。也就是說,再把彩色影像餵給 Kinect Fusion 前,需要先把解析度從 1920×1080 降到和深度影像一樣的 512×424,並使用 ICoordinateMapper 來做座標系統的轉換(這部分可以參考《K4W v2 C Part 5:簡單的去背程式》),讓彩色影像裡的每個像素都是對應到深度影像上同一個位置的像素。
Heresy 這邊的作法,是在讀取深度影像後,先透過 ICoordinateMapper 的 MapDepthFrameToColorSpace() 這個函式,來建立出一個把深度影像座標系統對應到彩色影像座標系統的表。這部分的程式大致上可以寫成下面的樣子:
IDepthFrame* pDepthFrame = nullptr;
if (pDepthFrameReader->AcquireLatestFrame(&pDepthFrame) == S_OK)
{
// read data
UINT uBufferSize = 0;
UINT16* pDepthBuffer = nullptr;
pDepthFrame->AccessUnderlyingBuffer(&uBufferSize, &pDepthBuffer);
// build color-depth mapping table
pMapper->MapDepthFrameToColorSpace(uDepthPointNum, pDepthBuffer,
uDepthPointNum, pColorPoint);
// …
}
其中,uDepthPointNum 就是深度點的數量,他的值是 512 * 424。pColorPoint 則是 ColorSpacePoint 的陣列,大小也是 512 * 424;在經過這樣的轉換後,pColorPoint 紀錄的就是「深度影像上同位置的一點、對應到彩色影像的位置」了。
而之後,在讀取到彩色養向後,就是要透過查表的方法,來把彩色影像的資料填入一張和深度影像一樣大的圖裡了。這邊的程式可以寫成:
IColorFrame* pColorFrame = nullptr;
if (pColorFrameReader->AcquireLatestFrame(&pColorFrame) == S_OK)
{
// read data
pColorFrame->CopyConvertedFrameDataToArray(
uColorBufferSize, pColorData, ColorImageFormat_Rgba);
// fill the color image frame with color-depth mapping table
BYTE* pColorArray = pColorImageFrame->pFrameBuffer->pBits;
for (unsigned int i = 0; i < uDepthPointNum; i)
{
const ColorSpacePoint& rPt = pColorPoint[i];
if (rPt.X >= 0 && rPt.X < iColorWidth &&
rPt.Y >= 0 && rPt.Y < iColorHeight)
{
int idx = 4 * ((int)rPt.X iColorWidth * (int)rPt.Y);
pColorArray[4 * i] = pColorData[idx];
pColorArray[4 * i 1] = pColorData[idx 1];
pColorArray[4 * i 2] = pColorData[idx 2];
pColorArray[4 * i 3] = pColorData[idx 3];
}
else
{
pColorArray[4 * i] = 0;
pColorArray[4 * i 1] = 0;
pColorArray[4 * i 2] = 0;
pColorArray[4 * i 3] = 0;
}
}
pColorFrame->Release();
}
在上面的程式碼裡面,Heresy 是先把彩色影像轉換成 RGBA 後、複製到 pColorData 裡面。之後,則是依序去讀取 pColorPoint 裡的座標位置(rPt),檢查確認位置是在彩色影像的座標範圍內後,再從 pColorData 裡面讀取該點的顏色、並將顏色填入 pColorArray 中。
這邊的 pColorArray 是 pColorImageFrame 這個 NUI_FUSION_IMAGE_FRAME 物件的底層資料,實際上就是直接去存取 pColorImageFrame->pFrameBuffer->pBits。 
而 pColorImageFrame 一樣是要透過 NuiFusionCreateImageFrame() 這個函式來做初始化,他的類型是 NUI_FUSION_IMAGE_TYPE_COLOR;特別要注意的,應該就是他的大小要和深度影像一樣大了~
NuiFusionCreateImageFrame(NUI_FUSION_IMAGE_TYPE_COLOR,
iDepthWidth, iDepthHeight, nullptr,
&pColorImageFrame);
在經過這樣的處理之後,pColorImageFrame 這張彩色影像就會是一個大小和深度影像一樣大、而且經過位置校正的彩色影像圖。
更新資料
在從 Kinect 獨到的原始資料處理好了之後,接下來就是透過 GetCurrentWorldToCameraTransform() 來取得最後的攝影機位置,並呼叫 ProcessFrame()、針對深度影像(pSmoothDepthFrame)和彩色影像(pColorImageFrame)做處理、整合到現有的 Volume 裡了。
pReconstruction->GetCurrentWorldToCameraTransform(&mCameraMatrix);
if (pReconstruction->ProcessFrame(
pSmoothDepthFrame, pColorImageFrame,
NUI_FUSION_DEFAULT_ALIGN_ITERATION_COUNT,
NUI_FUSION_DEFAULT_INTEGRATION_WEIGHT,
NUI_FUSION_DEFAULT_COLOR_INTEGRATION_OF_ALL_ANGLES,
nullptr, &mCameraMatrix) != S_OK)
{
cerr << "Can't process this frame" << endl;
}
在 INuiFusionColorReconstruction 的 ProcessFrame() 的參數裡,除了多了第二個是彩色影像之外、另外也多了第五個參數是「maxColorIntegrationAngle」(倒數第三個)。
這個參數的型別是浮點數、代表的是一個角度,目的是透過 surface normal 來控制是否要把彩色影像整合進去。範圍一般是在 0 – 90 之間;建議的預設值是 NUI_FUSION_DEFAULT_COLOR_INTEGRATION_OF_ALL_ANGLES、實際上是 180.0f。
不過說實話,個人搞不太清楚這個值的用法…以測試的結果來看,總覺得效果和 MSDN 的文字說明有點不同…所以,這部分就先跳過吧。(遠目)
檢視目前結果
要檢視目前的結果,在彩色版的部分,基本上應該只需要使用 CalculatePointCloud() 這個函式就夠了、不需要另外透過 NuiFusionShadePointCloud() 來做繪製。
INuiFusionColorReconstruction 的 CalculatePointCloud() 這個函式,在進行 ray casing 的時候,除了會產生 point cloud 的資料外,還會另外產生一張彩色影像,就是從指定的視角觀看目前的 volume 所看到的畫面。
它的使用方法基本上就是:
pPointCloudFrame,
pDisplayColorFrame,
&mCameraMatrix);
其中,第一個參數 pPointCloudFrame 就是類型是 NUI_FUSION_IMAGE_TYPE_POINT_CLOUD 的 NUI_FUSION_IMAGE_FRAME,代表從目前的攝影機角度(mCameraMatrix)做 ray casting 看到的點的資訊。
第二個參數 pDisplayColorFrame 則是類型為 NUI_FUSION_IMAGE_TYPE_COLOR 的 NUI_FUSION_IMAGE_FRAME,理論上就是從目前的攝影機角度(mCameraMatrix)看到的 vlomue 畫面。而這邊基本上就可以直接拿它來做顯示、預覽了~他的畫面基本上會像下面這樣:
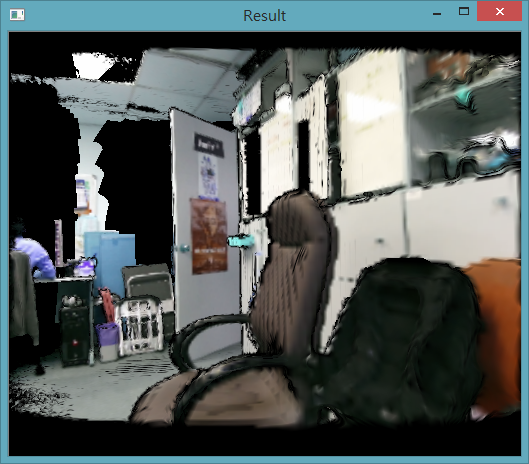
可以發現,它的色彩的細緻度比彩色攝影機的原生畫面差很多,這主要是因為降了解析度、又整合進 Vloume 的關係,基本上算是 Kinect Fusion 的技術限制了。
另外,這邊要注意的是,pDisplayColorFrame  的大小要和 pPointCloudFrame 相同。
產生多邊形(Mesh)
再產生多邊形的部分,基本上和沒有色彩的版本相同,也是 CalculateMesh() 就可以了;不同的地方,僅在於它輸出的格式變成了 INuiFusionColorMesh。這部分的程式可以寫成:
pReconstruction->CalculateMesh(1, &pMesh);
之後,就可以透過 pMesh 這個物件提供的介面,來讀取所需要的資訊了。
這篇就先寫到這裡了。如同一開始有提過的,由於這部分的內容很多都是基於沒有色彩的版本做延伸的,所以建議先把《Kinect Fusion Part 1:C API 基本使用》看過一遍會比較好。
而這篇的完整範例,請參考 GitHub 上的檔案。
這個完整的範例程式會使用 OpenCV 來做顯示,而按下鍵盤的「r」可以重新開始掃描、按下鍵盤的「o」則會把目前的結果寫到「E:\test.obj」這個檔案;如果沒有磁碟機 E:\、或是想寫到其他地方的話,就請自己修改 OutputSTL() 這個函式了。
沒意外的話,下一篇應該會大概提一下「INuiFusionMesh」變成「INuiFusionColorMesh」的基本操作。